

1.CTR介绍
点击率(click-through rate, CTR)是互联网公司进行流量分配的核心依据之一。比如互联网广告平台,为了精细化权衡和保障用户、广告、平台三方的利益,准确的CTR预估是不可或缺的。CTR预估技术从传统的逻辑回归,到近两年大火的深度学习,新的算法层出不穷:DeepFM, NFM, DIN, AFM, DCN……
从FM及其与神经网络的结合出发,能够迅速贯穿很多深度学习CTR预估网络的思路,从而更好地理解和应用模型。
2.CTR深度模型的推导思路
从原理上进行推导深度CTR预估模型,达到知其然也知其所以然的目的。
核心思路:通过设计网络结构进行组合特征的挖掘。
具体来说有两条:
- 从FM开始推演其在深度学习上的各种推广(下图红线)
- 从embedding+MLP自身的演进特点结合CTR预估本身的业务场景进行推演(下图黑线)

便于理解,我们简化了数据案例——只考虑离散特征数据的建模,以分析不同神经网络在处理相同业务问题时的不同思路。
3.FM:降维思路下的特征二阶组合
CTR预估本质是一个二分类问题。以移动端展示广告推荐为例,依据日志中的用户侧的信息(年龄、性别、婚否,手机上安装的app列表)、广告侧的信息(标题、类别、内容等)、上下文侧信息(渠道id等),去建模预测用户是否会点击该广告。
FM出现之前的传统的处理方法是人工特征工程加上线性模型(如逻辑回归Logistic Regression)。为了提高模型效果,关键就是特征工程,即是找到用户点击行为背后隐含的特征。如男性、大学生用户往往会点击游戏类广告,因此"男性且是大学生且是游戏类"的特征组合就是一个关键特征。但这本质仍是线性模型,其假设函数表示成内积形式一般为:
![]()
![]()
其中x为特征向量,w为权重向量,σ()为sigmoid函数。
但是人工进行特征组合通常会存在诸多困难,如维度灾难、特征难以被识别、特征难以组合等。为了让模型自动地考虑特征之间的二阶组合信息,线性模型推广为二阶多项式(2d−Polynomial)模型:
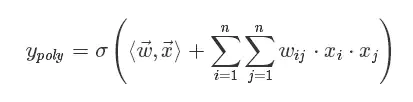
其实就是对特征向量两两点乘构成新特征(离散化之后其实就是"且"操作),并对每个新特征分配独立的权重,通过机器学习来自动获得这些权重。矩阵形式为:
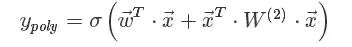
其中W2为二阶特征组合的权重矩阵,是对称矩阵。而这个矩阵参数非常多,为O(n2)。为了降低该矩阵的维度,可以将其因子分解(
FactorizationFactorization)为两个低维(比如n∗k)矩阵的相乘。则此时W2矩阵的参数就大幅降低,为O(nk)。公式如下:
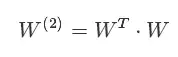
这就是Rendle等在2010年提出的因子分解机(Factorization Machines,FM)。FM的矩阵形式公式如下:
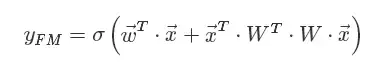
写成内积形式:
由于:
将上式改写成求和式形式:
其中vi向量是矩阵W的第i列。为了去除重复项与特征平方项,上式可以进一步改写成更为常见的FM公式:
对比二阶多项式模型,FM模型中特征两两相乘(组合)的权重是相互不独立的,它是一种参数较少但表达力强的模型。
4.从神经网络的视角看FM:嵌入后再进行内积
我们观察FM公式的矩阵内积形式:
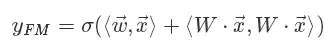
发现W*x部分就是将离散系数特征通过矩阵乘法降维成一个低维稠密向量。这个过程对神经网络来说就叫做嵌入(embedding)。所以用神经网络视角来看:
- FM首先是对离散特征进行嵌入。
- 之后通过对嵌入后的稠密向量进行内积来进行二阶特征组合。
- 最后再与线性模型的结果求和进而得到预估点击率。
其示意图如下。清晰起见,我们绘制的是神经网络计算图而不是网络结构图——在网络结构图中增加了权重W的位置。
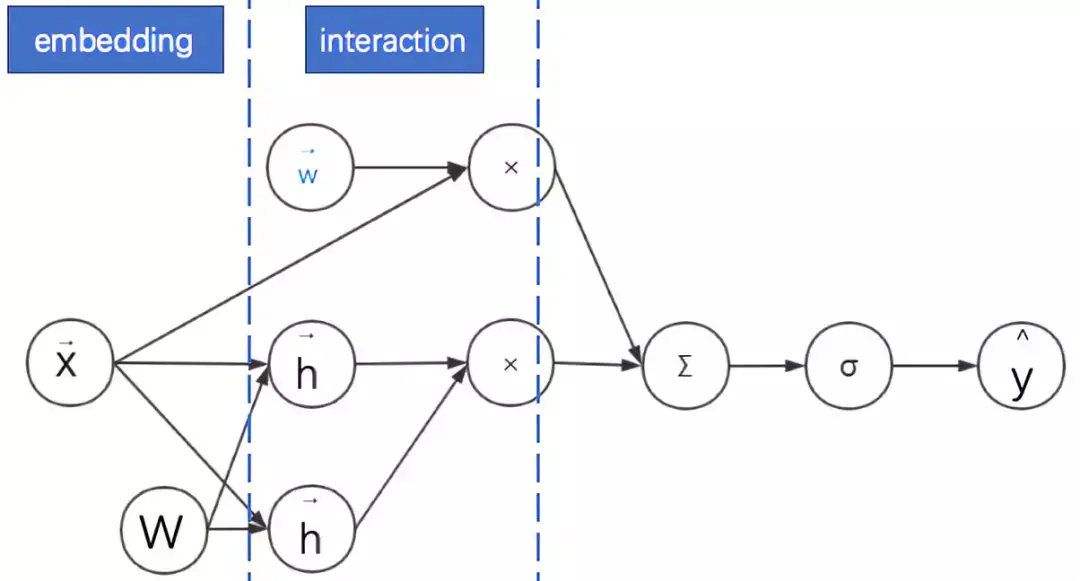
5.FM的实际应用:考虑特征领域信息
广告点击率预估模型中的特征以分领域的离散特征为主,如:广告类别、用户职业、手机APP列表等。由于连续特征比较好处理,为了简化起见,本文只考虑同时存在不同领域的离散特征的情形。处理离散特征的常见方法是通过one-hot编码转换为一系列二值特征向量。
然后将这些高维稀疏特征通过嵌入(embedding)转换为低维连续特征。前面已经说明FM中间的一个核心步骤就是嵌入,但这个嵌入过程没有考虑领域信息。这使得同领域内的特征也被当做不同领域特征进行两两组合了。
其实可以将特征具有领域关系的特点作为先验知识加入到神经网络的设计中去:同领域的特征嵌入后直接求和作为一个整体嵌入向量,进而与其他领域的整体嵌入向量进行两两组合。而这个先嵌入后求和的过程,就是一个单领域的小离散特征向量乘以矩阵的过程。
此时FM的过程变为:对不同领域的离散特征分别进行嵌入,之后再进行二阶特征的向量内积。其计算图图如下所示:
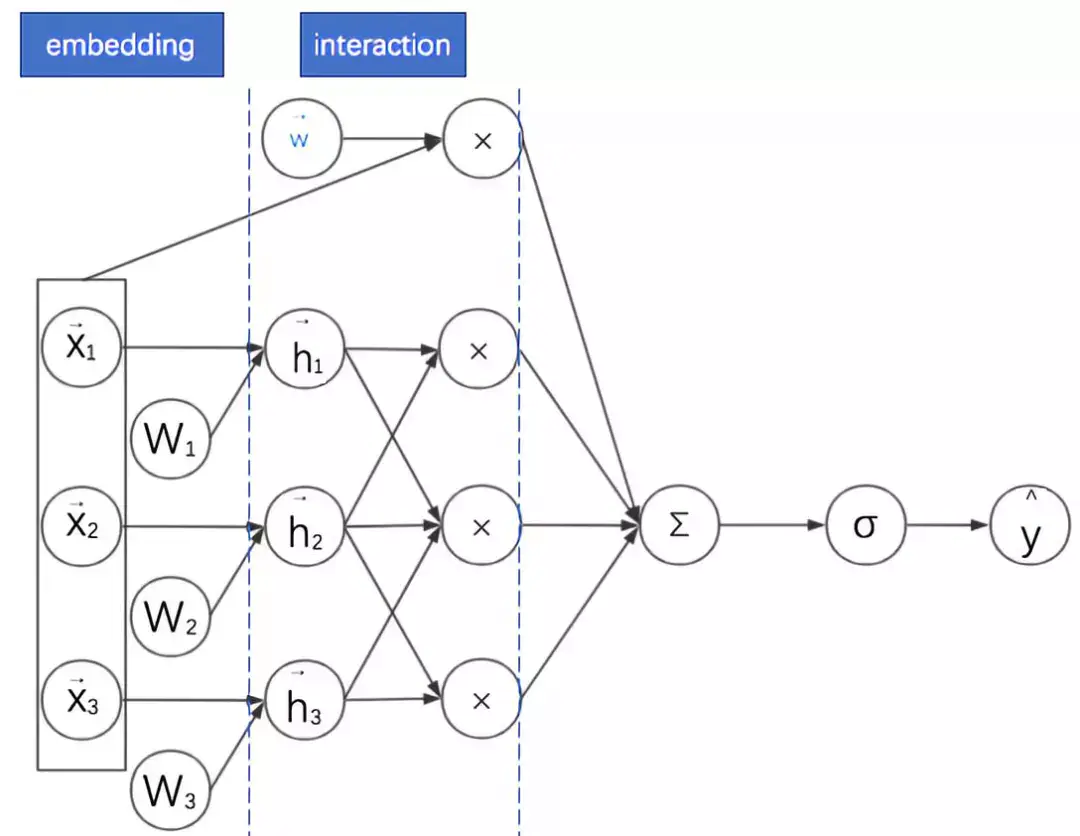
这样考虑其实是给FM增加了一个正则:考虑了领域内的信息的相似性。而且还有一个附加的好处,这些嵌入后的同领域特征可以拼接起来作为更深的神经网络的输入,达到降维的目的。接下来我们将反复看到这种处理方式。
此处需要注意,这与"基于领域的因子分解机"(Field-aware Factorization Machines,FFM)有区别。FFM也是FM的另一种变体,也考虑了领域信息。但其不同点是同一个特征与不同领域进行特征组合时,其对应的嵌入向量是不同的。本文不考虑FFM的作用机制。
经过这些改进的FM终究还是浅层网络,它的表现力仍然有限。为了增加模型的表现力(model capacity),一个自然的想法就是将该浅层网络不断"深化。"
6.embedding+MLP:CTR深度学习模型的通用框架
embedding+MLP是对于分领域离散特征进行深度学习CTR预估的通用框架。深度学习在特征组合挖掘(特征学习)方面具有很大的优势。比如以CNN为代表的深度网络主要用于图像、语音等稠密特征上的学习,以W2V、RNN为代表的深度网络主要用于文本的同质化、序列化高维稀疏特征的学习。CTR预估的主要场景是对离散且有具体领域的特征进行学习,所以其深度网络结构也不同于CNN与RNN。
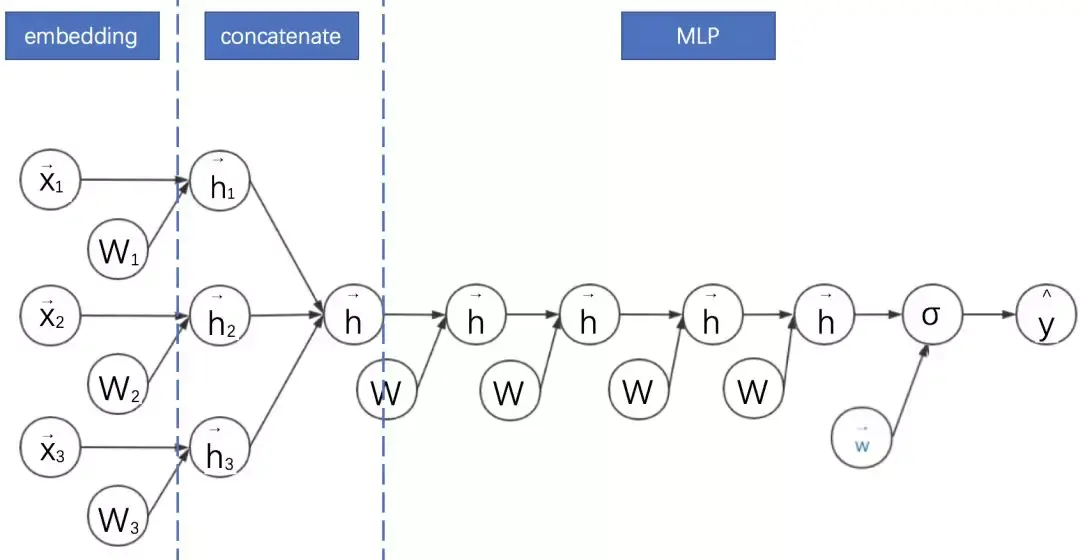
embedding+MLP的过程如下:
1. 对不同领域的one-hot特征进行嵌入(embedding),使其降维成低维度稠密特征。
2. 然后将这些特征向量拼接(concatenate)成一个隐含层。
3. 之后再不断堆叠全连接层,也就是多层感知机(Multilayer Perceptron, MLP,有时也叫作前馈神经网络)。
4. 最终输出预测的点击率。
其示意图如下:
embedding+MLP的缺点是只学习高阶特征组合,对于低阶或者手动的特征组合不够兼容,而且参数较多,学习较困难。本文今天主要讲到此,实现了由FM到深度神经网络表示的转变,后续会继续发文讲解改进的其他模型。
文章来源于网络,如若侵权,请联系站长删除。
本站承接各类商务合作,如有合作需求,请联系我们。
相关推荐
-
淘宝怎么设置不包邮地区(淘宝卖家不包邮运费怎么设置)
关键词:发货模板 设置 适用行业:所有行业 适用店铺:所有店铺 摘要:开淘宝店的商家都知道每次发货给买家都需要运费,所以在店铺后台都有一个设置运费物流工具版块,但是通常在修改运费模板的时候,所关...
-
ebay美国站点市场分析(美国电商市场发展特点是什么)
美国是世界上最大的经济体,是电子商务最发达、市场成熟度最高的国家之一。对于中国跨境出口卖家来说,美国仍是第一大目标市场。 中美贸易战和“新冠”疫情两大不确定性因素的影响,并没有改变包括美国在内的全球跨...
-
入门网络营销要知道什么(分析入门必学知识)
网络营销包含的内容特别广,什么新媒体运营、SEO、SEM、线上活动策划都属于网络营销的范畴。今天的文章,我们来总结下网络营销技巧。 一、推广目标 首先,必须确定推广目标,需定性和定量。定性是指明确推广的目...
-
关键词怎么写4大诀窍分享(亚马逊搜索关键词如何填写)
经常有粉丝朋友问我,做亚马逊关键词的排名到底该怎么去打?今天这篇文章,我来一次性给大家讲清楚。 作为运营,你首先要明白什么叫做关键词 ——关键词是由几个单词组成的一个词组,而且这个词组还带有相应的搜索...
-
抖音认证需要什么操作(超详细的抖音蓝V开通流程)
随着5G时代来临,短视频将彻底爆发,抖音从2016年出来到现在6个年头,发展迅猛,突飞猛进,现在一跃而起成为短时频老大,成为市场占有率高的短视频平台,日活跃人数七月份达到3.2亿,相当于一个每天有3.2亿人逛来...
-
阿里巴巴物流配送方式(阿里巴巴的物流模式是什么)
前些天在朋友圈感慨,说现在像桂林这样的三线城市,电商物流也可以实现晚上下单、次晨送达了。 话音未落,不少帝都魔都的朋友就开始来嘚瑟了,包括但不仅限于: 我们这里 在天猫旗舰店购物最快2小时就可以...
-
红海市场和蓝海市场分别有什么特征(红海市场与蓝海市场的区别是什么)
很多淘宝新手都不知道,红海市场和蓝海市场是什么意思? 简单来说,蓝海市场就是竞争小,红海市场就是竞争大。 但是如果你要选品的话,可不能这样非黑即白地对待每个产品,这里我们要细分一下每个产品,需要对每...
-
淘宝直播在哪里看(快速上直播广场首页)
如果您是一位喜欢逛淘宝的用户们的话,那么相信大家一定对近日的热门话题:淘宝直播并不陌生。现如今,淘宝已经成为很多用户们生活中必不可少的一部分,只要动动手指就可以送货上门。如今手机淘宝又推出了强大的...
-
怎么开游戏直播抖音教程(怎么开启抖音游戏直播)
无论你是游戏直播的新手还是经验丰富的主播,都有可能对如何充分提高游戏直播效果和粉丝数而感到困惑。为了帮助主播,我们收集了一些游戏直播常用的小技巧,以充分提高你的直播效果。 1 选择感兴趣的游戏 强烈建...
-
新手微商该怎么起步(新手怎么开始做微商)
新手做微商怎么做如何起步?新手做微商怎么找客源?现在说起微商这个词,并不像一年前那么陌生了,14年初的时候,微商还是很新颖的一个词,那会只是知道一些,但是并没有打算去做,觉得微商不是很靠谱,但是15年...